Unification in Elixir

Pattern matching is a pervasive and powerful tool in Elixir. This isn't too surprising if you know a little about the history of Elixir's parent language, Erlang. Erlang was originally inspired by and written in Prolog, a logic programming language where pattern matching has first-class support.
In Elixir, you might see an expression like this:
[x, [2, y]] = [1, [2, 3]]When this expression is evaluated, the variables x and y on the left are assigned to values 1 and 3, respectively. The symbol =, called the match operator, attempts to associate variables with values that allow the two sides be equal. When a unique match is possible, variables are assigned and made available to the runtime. When a match isn't possible, Elixir raises a MatchError:
[x, [2, y]] = [1, 2]
** (MatchError) no match of right hand side value: [1, 2]Elixir allows one-sided pattern matching, where variables can appear only on the left side of the match operator. There are probably very good practical reasons for this choice, but there is no logical reason why variables couldn't appear on both sides.
To help you get a better appreciation for how pattern matching works, and to tease the potential of more general logic programming, I'll walk through the implementation of two-sided pattern matching, also known as unification. Unification is an algorithm for solving symbolic equations. Described below are the ingredients and steps to make unification seem relatively intuitive and to allow you play with it yourself.
What is unification?
Like Elixir's pattern matching, unification is an assertion of equality, followed by variable assignment when the assertion is true. Unification operates on a pair of terms. These terms may be variables or atomic values (numbers, strings, atoms) or a list of terms. Successful unification produces a mapping from variables to values (other terms), so that the original assertion is satisfied. This mapping is a substitution.
Unlike Elixir's pattern matching, the substitution that results from successful unification may contain variables with only partially known values. This allowance for uncertainty is a powerful feature. New information may come along that further refines existing variables, adds new variables to the substitution, or refutes the substitution and causes unification to fail.
Here are some notional examples of successful unification, along with the resulting substitutions:
#1
unify(1, 1)
identity; empty substitution
---
#2
unify(x, x)
identity; empty substitution
---
#3
unify(x, 1)
x => 1
---
#4
unify(x, [1, y])
x => [1, y]
---
#5
unify([x, [2, y]], [1, [2, [x, 4]]])
x => 1
y => [x, 4]This interface is slightly different than the implementation shown below, but the spirit is the same. The first two example are identity relations: true statements that don't provide any new information. Partial knowledge is shown in the 4th example: x is assigned to a list, but y is unknown. In example 5, the substitution says that variable y is assigned to a list that contains variable x. But since x is assigned to 1, the value of y is actually [1, 4]. This kind of indirection in substitutions is common. You'll see below how to simplify variable assignments in cases like this.
These pairs of terms fail to unify:
#1
unify("one", "two")
---
#2
unify([x, 2], :a)
---
#3
unify([x, x], [1, 2])Two different atomic values aren't equal, and a list can never be equal to an atomic value. The 3rd case says that a list of two identical elements can't be equal to a list with two different elements.
If all of this still seems a bit murky, don't panic. The ideas are pretty straightforward, and once you see the code and put it to use, I think things will fall into place. Next, I'll define more precisely what is meant by term, variable, and substitution.
What is a term?
A term is a collective label for the kinds of values that can be unified. To distinguish from the broader class of Elixir terms, I'll use the type uterm when discussing unification. A uterm can be either an atomic value, a variable, or a list of uterm values. For this discussion, a list will be the only collection type in the definition of uterm.
As an Elixir typespec, a uterm can be defined as
@type atomic :: number | atom | binary
@type uterm :: atomic | variable | [uterm](The variable type will be defined shortly.) Notice that the definition of uterm is recursive. If x, y, and z are variables, then examples of valid terms include 1, x, "term", [1, 2], [x, :a, 1, "one"], and [[x, y], [[1, [2, z]]].
What is a variable?
A variable is placeholder for a value. That value can be any term, including another variable or a list that contains variables. Variables with different names, like x and y, may hold different values. If variable x appears more than once in the terms being unified, every instance of x must have the same value. And once the value of a variable is set, it can't have any other value. The term [x, y] might successfully unify with both [1, 2] and [1, 1]. The term [x, [1, x]] would successfully unify with [:a, [1, :a]], but not with [3, [1, 2]].
There are a number of ways to define a variable in code. Whatever the approach, it must be possible to uniquely identify different variables, and a variable must be distinct from a number, binary, atom, or list. Since we're working in Elixir, an idiomatic way to represent a variable is as a struct, like so
defmodule Var do
alias Var
@type t :: %Var{id: any}
defstruct [:id]
@spec new(any) :: Var.t()
def new(id), do: %Var{id: id}
endThis defines a type Var.t and a constructor Var.new to be used outside the module. The variable type in uterm can alias the struct type:
@type variable :: Var.t()This struct representation makes it convenient to use Elixir pattern matching when working with variables.
When constructing a variable, there doesn't need to be any relationship between the identifier and the Elixir variable name. It's valid to type x = Var.new(1). Just be careful to use different identifiers for different variables. As a convention, I'll define variables with an atom identifier that corresponds to the Elixir variable name, as in x = Var.new(:x) and y = Var.new(:y).
What is a substitution?
As already stated, a substitution is a mapping from variables to values, where a value can be any term. Unsurprisingly, an Elixir Map is an excellent choice to represent a substitution. This type definition serves as handy documentation:
@type substitution :: %{} | %{variable => uterm}Because the substitution is represented as an ordinary map, standard functions like Map.fetch and Map.put can be used to query and update a substitution.
A substitution will often have indirect relationships, where one variable is associated with other variables, and those variables depend on other variables, and so on. To resolve the value of a term, it may be necessary to hop among associated variables–to walk the web of relationships. Two kinds of walks will be used later, one shallow and one complete. The shallow version, which, according to convention, I just call walk, is used in the implementation of unification. The complete walk, which I call simplify, is used to present the final result of unification in the simplest form possible.
A walk of a term is performed against the current substitution. In walk, the term is first looked up as a key in the substitution. If the key is present, the walk is applied recursively to its associated value. If, at some point in the recursion, the key is absent, the walk returns the term. Here's an implementation of the shallow walk:
@spec walk(substitution, uterm) :: uterm
def walk(sub, term) do
case Map.fetch(sub, term) do
{:ok, t} -> walk(sub, t)
:error -> term
end
endFor the substitution %{x => y, y => 1}, a shallow walk on x first finds the term y, then the term 1, and then returns 1. If x is walked on %{x => y, y => [1, z]}, the walk stops when the list term [1, z] is reached, because a list can't be a key in the substitution; only variables can be keys.
The function simplify starts with a shallow walk, but then descends into list terms and recursively applies simplify to their contents. Here's the code:
@spec simplify(substitution, uterm) :: uterm
def simplify(sub, term) do
case walk(sub, term) do
[h | t] -> [simplify(sub, h)| simplify(sub, t)]
term -> term
end
endIf the the shallow walk ends at a list, a new list is formed by applying simplify to the head and tail. Otherwise, the result of walk is returned. When x is simplified in %{x => y, y => [1, z], z => 2}, the result is [1, 2].
Putting it all together
At this point, all the data structures and basic operations have been discussed. Now I'll step through the implementation of the unification algorithm.
The public function for unification is
@spec unify(substitution, uterm, uterm) :: {:ok, substitution} | :error
def unify(sub, term1, term2) do
...
endWhen unify succeeds, it returns an :ok tuple with an updated substitution; otherwise, :error is returned.
When unify is first called, it will often be given an empty substitution, which is the same as saying that there's no prior knowledge about the variables. The assertion that the two terms are equivalent constrains the relationships between variables present in the terms. Information about these constraints is captured as an updated substitution. The substitution acts like a working memory as unification proceeds through a series of relatively simple steps.
Step 1: Walk
If one or both terms are variables, the values of those variables are needed before equivalence can be tested. Variable values are obtained by a shallow walk with the given substitution. These walked values are passed as arguments to do_unify, a private function that does the heavy lifting:
def unify(sub, term1, term2) do
do_unify(sub, walk(sub, term1), walk(sub, term2))
endWith a shallow walk as the first step, unification is able to navigate variable relationships incrementally, testing for equivalence and new information at each stage of the descent. Remember that walk returns the first value that isn't a key in the substitution. This could be a variable for which there is not yet a value, a list, or an atomic value. Each of these possibilities is dealt with, in turn, using multiple clauses of do_unify.
Step 2: Equivalence
First, test for the equivalence of the two walked terms. If the two terms passed to do_unify have equivalent values, then stop and return {:ok, sub}:
defp do_unify(sub, term1, term2) when term1 == term2 do
{:ok, sub}
endWhen the terms are lists, unification succeeds if the lists are equivalent. This is true even if the lists contain variables. Note that [x, 2] == [x, 2] is true for all values of x.
Steps 3 and 4: Variable
If the first term in do_unify is a variable (a Var struct), update the substitution by associating the variable with the second term. If the first term isn't a variable, perform the same test on the second term:
defp do_unify(sub, %Var{} = var, term) do
extend(sub, var, term)
end
defp do_unify(sub, term, %Var{} = var) do
extend(sub, var, term)
endwhere extend is:
@spec extend(substitution, variable, uterm) :: {:ok, substitution}
defp extend(sub, var, term) do
{:ok, Map.put(sub, var, term)}
endThis is the step where new knowledge is recorded in the substitution.
When unify(%{}, x, 1) is called, there's an assertion that x == 1. Since this assertion doesn't conflict with the initially empty substitution, the substitution is updated to %{x => 1}. The same result is obtained from unify(%{}, 1, x) because of the symmetry enforced by the pair of do_unify clauses that test for a Var struct.
Step 5: List
If both terms are non-empty lists, first unify the heads of the two lists. If the heads successfully unify, return the unification of the tails. It looks like this:
defp do_unify(sub, [h1 | t1], [h2 | t2]) do
with {:ok, sub} <- unify(sub, h1, h2) do
unify(sub, t1, t2)
end
endThis is the recursive step in the unification algorithm. Notice that the with block returns :error if the heads don't successfully unify.
Step 6: Remainder
If the walked terms passed to do_unify don't satisfy any of the previous patterns, then the two terms can't be unified. In this case, just return :error:
defp do_unify(_sub, _term1, _term2) do
:error
endThis clause will be reached when the terms are different atomic values, like 1 and :one, when one term is a constant and the other is a list, or when both terms are empty lists.
That's it! This completes implementation of unification. The full code listing can be found here:
Unification algorithm in Elixir.
Presenting results
Suppose you're given the substitution %{x => y, y => [1, z], z => 2} and asked to reduce the variables to their simplest possible forms. That means walking the relationships in the substitution as far as possible. This is the job of simplify that was introduced earlier. Here's a usage example:
x = Var.new(:x)
y = Var.new(:y)
z = Var.new(:z)
sub = %{x => y, y => [1, z], z => 2}
simplify(sub, [x, y, z])This application of simplify returns [[1, 2], [1, 2], 2]. Notice that a new term, [x, y, z], was created to collect the simplified values.
Examples
This can all seem a bit dry and technical without meaningful examples. Here are two simple examples that hint at more general possibilities.
Yes, and
Here are three lists, each with variables:
[x, y, z] = for i <- [:x, :y, :z], do: Var.new(i)
l1 = [1, y, z]
l2 = [x, 2, z]
l3 = [x, y, 3]I assert that all of these lists are equivalent; that is, each list holds the same set of values. Find values for x, y, and z that satisfy the assertion. It's easy to see that the answer is [x, y, z] = [1, 2, 3]. Let's use unification to prove this.
First, unify l1 and l2 on an empty substitution to find
{:ok, s12} = unify(%{}, l1, l2)The updated substitution, s12 = %{x => 1, y => 2}, holds information about x and y, but not z. Feed this substitution into the unification of l2 and l3:
{:ok, s23} = unify(s12, l2, l3)This yields the substitution s23 = %{x => 1, y => 2, z => 3}. All the variables now have atomic values. Unification of l1 and l3 using the previous substitution will work just fine, but it doesn't add any new information.
All of these steps can be captured in one block of code that looks like a pipeline, where the substitution from the previous step is fed to unify in the next step:
with {:ok, s12} <- unify(%{}, l1, l2),
{:ok, s23} <- unify(s12, l2, l3),
{:ok, s13} <- unify(s23, l1, l3) do
simplify(s13, [x, y, z])
endThis returns the expected result [1, 2, 3].
The pipeline above encodes that idea that l1 = l2 and l2 = l3 and l1 = l3; it's asserting that the equalities are jointly true. This is an example of logical conjunction. Successful conjunction produces a single substitution that jointly satisfies the assertions. Failure of any one of the assertions causes the whole conjunction to fail. It's all or nothing.
Choices, choices
Each variable in a substitution has a single value. And a single substitution captures one set of variable assignments. But what if there are choices for variable values? What if x can be 0 or 1, or :up or :down? If a substitution is able to hold only one value per variable, then a collection of substitutions can encode multiple choices.
Logical conjunction asserts that statements are jointly true. In a logical disjunction, the statements may be separately true. Like we saw in the example of the three-way list merge, conjunction involves chaining assertions together to create a single substitution that represents joint truth. Disjunction, on the other hand, creates multiple branches of truth, a collection of substitutions, each of which captures a different choice. It's time for an example.
Imagine a person that can move only one step to the left or one step to the right, but we don't know what choice the person will make beforehand (this might represent a random walk). What can we say about the person's possible locations after a number of steps?
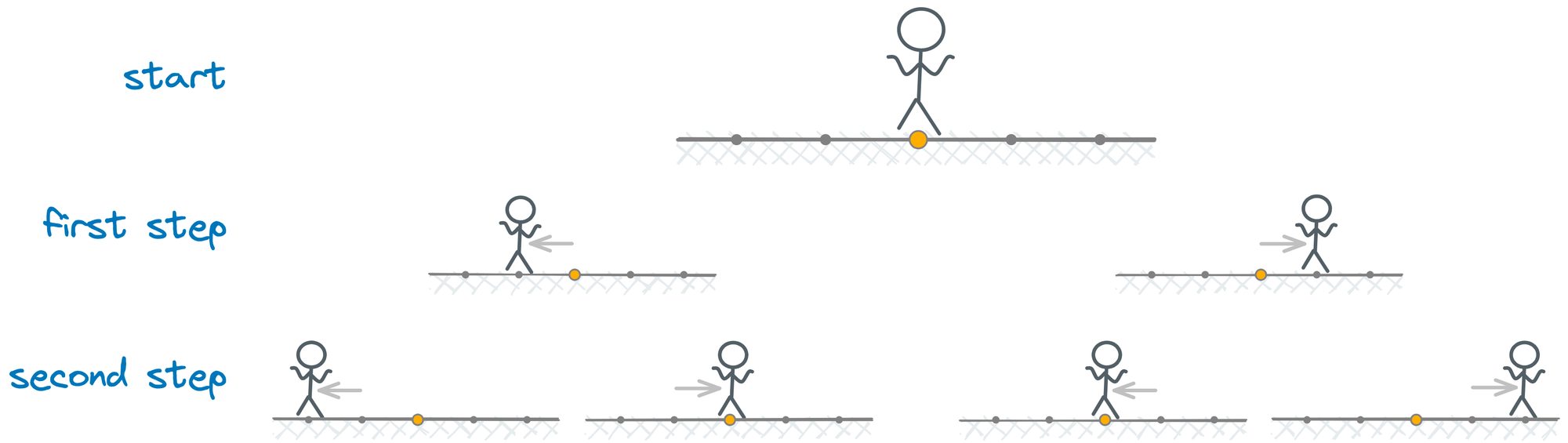
For the first step, the direction d1 will be either :left or :right. This can be expressed as two unifications, both starting with an empty substitution:
d1 = Var.new(:d1)
{:ok, sl} = unify(%{}, d1, :left)
{:ok, sr} = unify(%{}, d1, :right)
[sl, sr] = [%{d1 => :left}, %{d1 => :right}]The list of substitutions exhibits the two choices for d1. Another way to write this, for reasons you'll see very soon, is
d1 = Var.new(:d1)
[sl, sr] =
[%{}]
|> Enum.flat_map(fn sub ->
{:ok, sl} = unify(sub, d1, :left)
{:ok, sr} = unify(sub, d1, :right)
[sl, sr]
end)Convince yourself that this returns the same result (see the docs for Enum.flat_map).
What's the situation after two steps? The choices are the same (:left or :right), but each choice for the second step is compounded with the choice from the first step. The first step is either :left or :right, and the second step is either :left or :right. This is a conjunction of two disjunctions. The result from the first step is chained with the result from the second step. Here's what that looks like in code:
d2 = Var.new(:d2)
[sl, sr]
|> Enum.flat_map(fn sub ->
{:ok, sl} = unify(sub, d2, :left)
{:ok, sr} = unify(sub, d2, :right)
[sl, sr]
end)The result from the first step is piped to flat_map. This has the same structure as the code from the first step. The two-step result is
[
%{d1 => :left, d2 => :left},
%{d1 => :left, d2 => :right},
%{d1 => :right, d2 => :left},
%{d1 => :right, d2 => :right}
]
There are four substitutions, each displaying a pair of binary choices.
A third step will produce eight substitutions. Can you see how to pipe the previous result into a similar flat_map expression that contains a variable d3? The pattern can certainly be leveraged to create a more ergonomic way to generate the substitutions for any number of steps. That's left to you as an exercise!
Wrapping up and looking ahead
You now have in your toolbox a working Elixir implementation of unification. My hope is that you also understand how unification works, perhaps well enough to read about other implementations or to write your own version in a different language. If your understanding is still a little hazy, have some fun experimenting with the code. Create your own examples. Tweak the algorithm and see what happens. Add some helper functions to streamline tedious steps.
Even on its own, unification, like Elixir's pattern matching, is a powerful tool. But things get so much more interesting when new operations are layered on top of unification. The examples above hint at how conjunction and disjunction might be implemented more generally. With only equality (via unification), conjunction, and disjunction, it's possible to create a very capable logic programming language. To read more about this, take a look at some of the sources that inspired this post:
microKanren: A Minimal Functional Core for Relational Programming
Relational Programming in miniKanren: Techniques, Applications, and Implementations
All of these references use a Lisp dialect as the host language. For an Elixir-flavored miniKanren, see Logos, a library I wrote that is still very much a work-in-progress.
In a follow-up post, I'll go into some of the core operations defined in microKanren and how they can be leveraged to build more powerful logical abstractions.
Have fun and logic on!